
Abri um repositório meu de dois anos atrás. Continuava público no GitHub, eu citava ele no portfólio em entrevista, e eu nunca tinha relido o código depois de submeter. Esse fim de semana resolvi reler.
Achei cinco anti-padrões. No meu próprio código, escrito por mim. Mas o tipo de problema que eu vejo aparecer em pipelines reais de empresa grande, não só em case de entrevista.
Resolvi escrever sobre porque é mais honesto criticar o próprio código do que apontar dedo pra repo dos outros. E porque se você tem um repo público de dois anos atrás citado no seu portfólio, você provavelmente também tem pelo menos três desses cinco.
A credencial do banco estava dentro da função
def load_data_to_snowflake(df_merged):
conn = snowflake.connector.connect(
user='thaiscxxx',
password='xxx*',
account='xxx'
)Mascarei com xxx antes de subir, mas o padrão de design é o problema, não a string. Credencial dentro da função significa que cada task que precisa do Snowflake duplica essa conexão, rotacionar a senha exige tocar em código, e auditoria precisa varrer o repo inteiro pra saber quem conecta no banco.
A versão honesta usaria um Hook do Airflow (SnowflakeHook) ou variável de ambiente, com a conexão gerenciada fora do código:
from airflow.providers.snowflake.hooks.snowflake import SnowflakeHook
hook = SnowflakeHook(snowflake_conn_id='snowflake_default')Conexão criptografada, rastreável, e nunca aparece em pull request.
O pipeline perdia paralelismo de graça
t1 >> t2 >> t3 >> t4t1 validava students.json. t2 validava missed_days.json. Eu encadeei os dois em sequência, mas eles são independentes. Não existe motivo pra t2 esperar t1 terminar. Em arquivo pequeno, dá quase no mesmo. Quando o JSON pesa gigabytes e validação leva minutos, paralelizar cai a duração pela metade.
A versão correta seria:
[t1, t2] >> t3 >> t4Quem lê o pipeline hoje entende que validação roda em paralelo e depois faz o join. Quem lia o original ia assumir que existia alguma dependência escondida que não existia.
![Como eu escrevi vs como deveria ser: t1 » t2 » t3 » t4 em série contra [t1, t2] » t3 » t4 com validações em paralelo](/2026/06/02/code-review-meu-codigo-antigo/images/02-serie-vs-paralelo.png)
Os dados estavam dentro da imagem Docker
No Dockerfile:
COPY files/students.json /students.json
COPY files/missed_days.json /missed_days.jsonEmbuti o dado de entrada na imagem. Cada rebuild da imagem assume o mesmo dado. Pra rodar o pipeline com um JSON diferente, eu teria que rebuildar a imagem ou modificar o código. Acoplamento entre artefato de execução e dado de entrada, no mesmo lugar.
A regra que eu cobrava de outros e ignorei no meu próprio repo: imagem é imutável, dado é mutável. Dado entra via volume montado, S3, GCS, ou parâmetro de execução. Nunca dentro da imagem.
O DAG rodava todo dia sobre dado estático
with DAG('migrate_student_data_to_snowflake',
schedule_interval=timedelta(days=1),
catchup=False) as dag:Agendei o pipeline pra rodar todo dia. O dado de entrada é os dois JSONs estáticos copiados pra dentro da imagem (o anti-padrão acima). Rodar todo dia significa processar exatamente os mesmos arquivos, gerar exatamente os mesmos registros, e tentar inserir tudo de novo na mesma tabela. Na segunda execução, o write_pandas duplicaria as linhas. Na terceira, duplicaria de novo.
O dado é estático. A escolha correta seria schedule_interval=None (dispara só manual ou por trigger) ou um sensor que detecta arquivo novo no bucket. Agendar pipeline sem fonte mutável é cerimônia: gasta worker slot todo dia, dispara alerta se quebrar, polui o histórico de execução. E quando você precisa rodar de verdade com dado novo, a operação fica indistinguível do ruído de fundo.
Era pra rodar uma vez. Eu agendei pra rodar todo dia. Sutil, mas o tipo de coisa que cria DAG cerimonial em produção: pipeline que existe sem motivo de existir naquele intervalo.
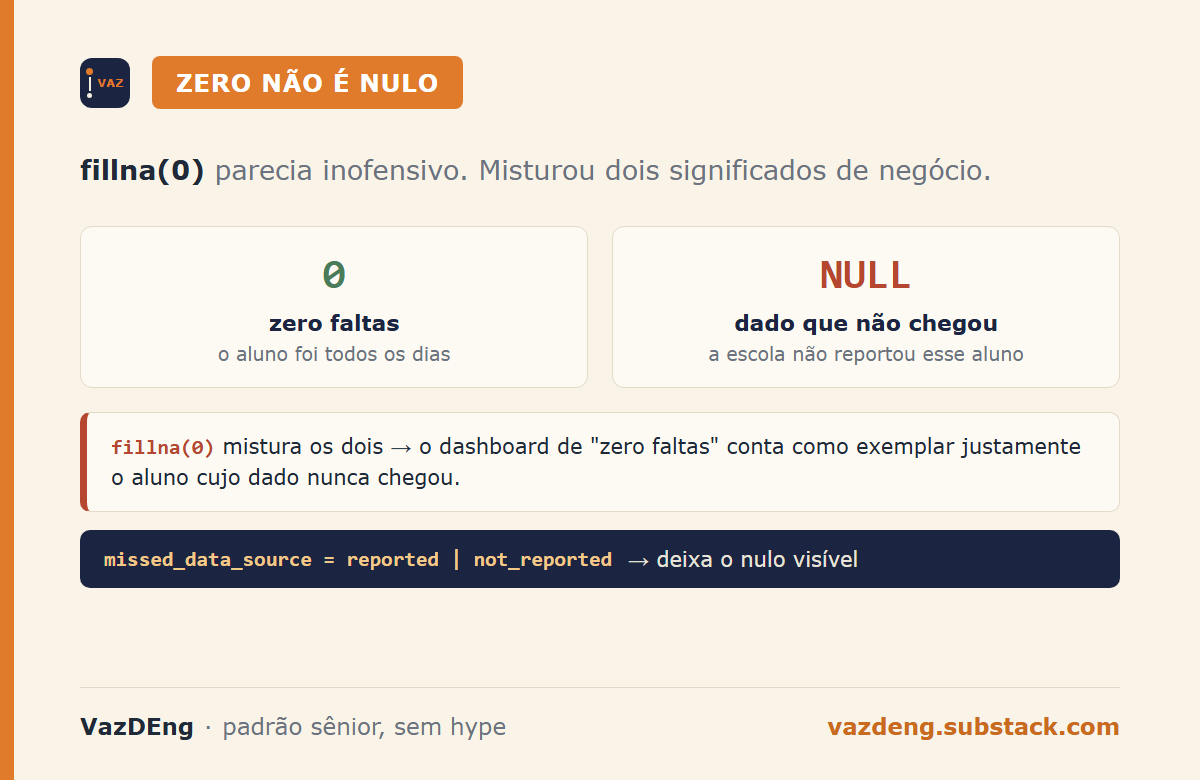
O fillna(0) apagou um sinal importante
df_merged['missed_days'].fillna(0, inplace=True)Quando um aluno aparece em students.json mas não em missed_days.json, o join deixa missed_days nulo. Substituí por zero. Parecia certo na hora.
Zero falta tem significado de negócio: aluno foi todos os dias. Ausência de registro tem outro significado: a escola não passou o dado desse aluno. Misturar os dois mascara um problema de qualidade de dado upstream. O dashboard que filtra alunos com “zero faltas” vai contar como exemplares justamente os alunos cujo dado nunca chegou.
A versão honesta deixaria nulo e abriria coluna nova marcando se houve registro:
df_merged['missed_data_source'] = df_merged['missed_days'].notna().map(
{True: 'reported', False: 'not_reported'}
)Pequena mudança, completamente diferente o que o dashboard mostra.
O incômodo de revisar código próprio
Reescrever esses cinco trechos hoje levaria uma hora. O incômodo de admitir publicamente que estavam errados é maior do que a hora. Mas o repo continuou público com os defeitos, e eu cito esse repo no meu portfólio. Manter o repo intacto e fazer review honesto em cima é mais útil pra quem está aprendendo do que apagar a história e fingir que sempre escrevi código bom.
Se você tem um repo público antigo que continua no seu portfólio, abre ele essa semana. Vai achar pelo menos três desses cinco.