
Tem dev hoje fazendo onboarding em time sênior que nunca escreveu um GROUP BY na vida. Aprendeu ORM antes de SQL. Acha que df.groupby() resolve. Quando a query trava porque o plan de execução virou full scan em tabela de 80 milhões de linhas, copia o erro pro ChatGPT, cola a resposta, e quando trava de novo, copia de novo. Loop infinito.
Esse dev é o que o Akita chama de codificador. E a IA está acelerando a extinção dele.
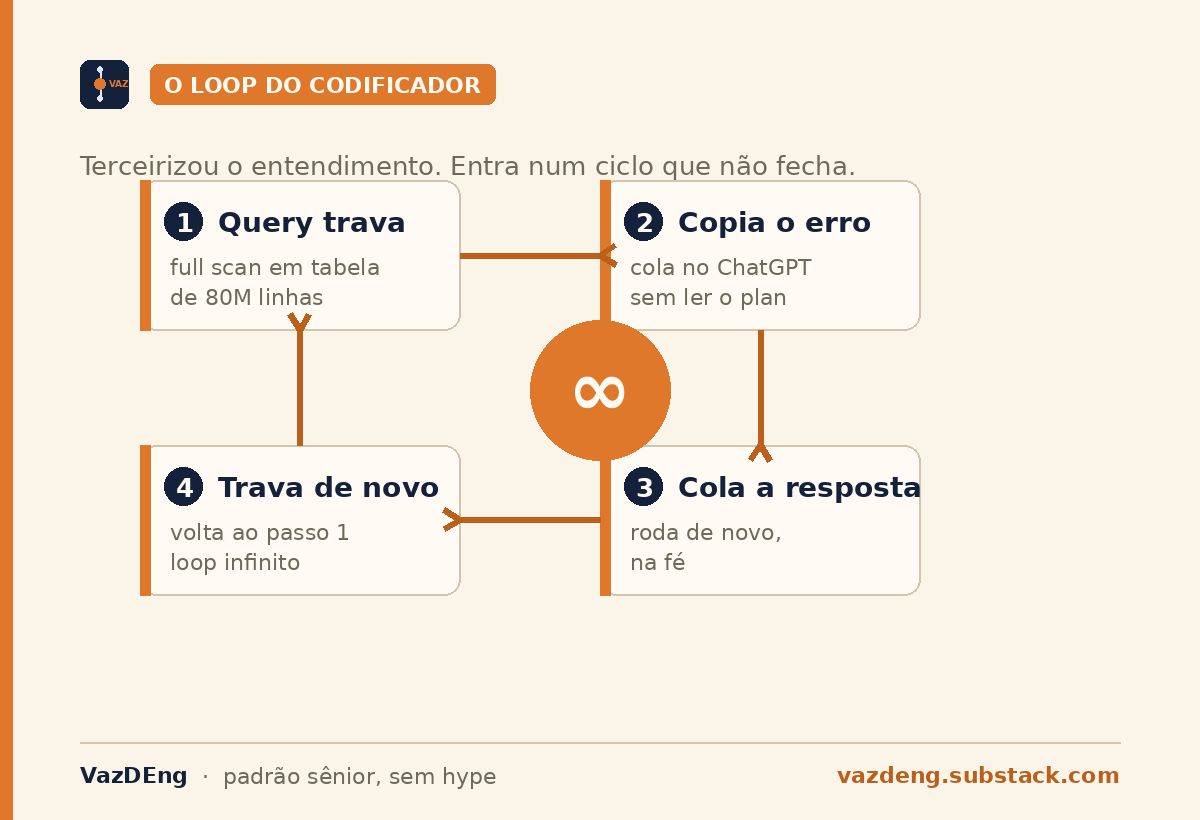
O codificador terceirizou o entendimento
Eu aprendi SQL antes de qualquer framework, porque era o único jeito de falar com o banco. Hoje é o contrário. Framework antes de SQL. ORM antes de SQL. pandas antes de SQL. Camadas e mais camadas de abstração que escondem a query que de fato vai rodar.
O problema da abstração não é a abstração. É que ela esconde o custo. Você acha que User.objects.filter().select_related().prefetch_related() é cheap. Não é. É um JOIN que pode estourar memória se você não souber por que está rodando JOIN, em quantas tabelas, com qual cardinalidade. O ORM escreve a query certa em 70% dos casos. Os 30% restantes destroem teu cluster.
Em pipeline real, abstração não cabe
Pipeline de DE moderno processa bilhões de linhas por dia. Toda decisão de query custa minutos vezes cluster vezes DBU vezes dia vezes mês. A diferença entre uma query bem escrita e uma gerada por ORM despreparado é fator 10 a 100x no custo final.
Caso concreto que apareceu numa consultoria: pipeline de fechamento contábil em fintech brasileira. ORM gerando 47 subqueries pra coisa que SQL nativo resolve em 1 CTE com WINDOW. Custo Databricks/Snowflake: R$ 8 mil/mês. Depois que alguém finalmente escreveu a query em SQL puro, R$ 800/mês. Mesmo resultado de negócio, fator 10x de diferença.
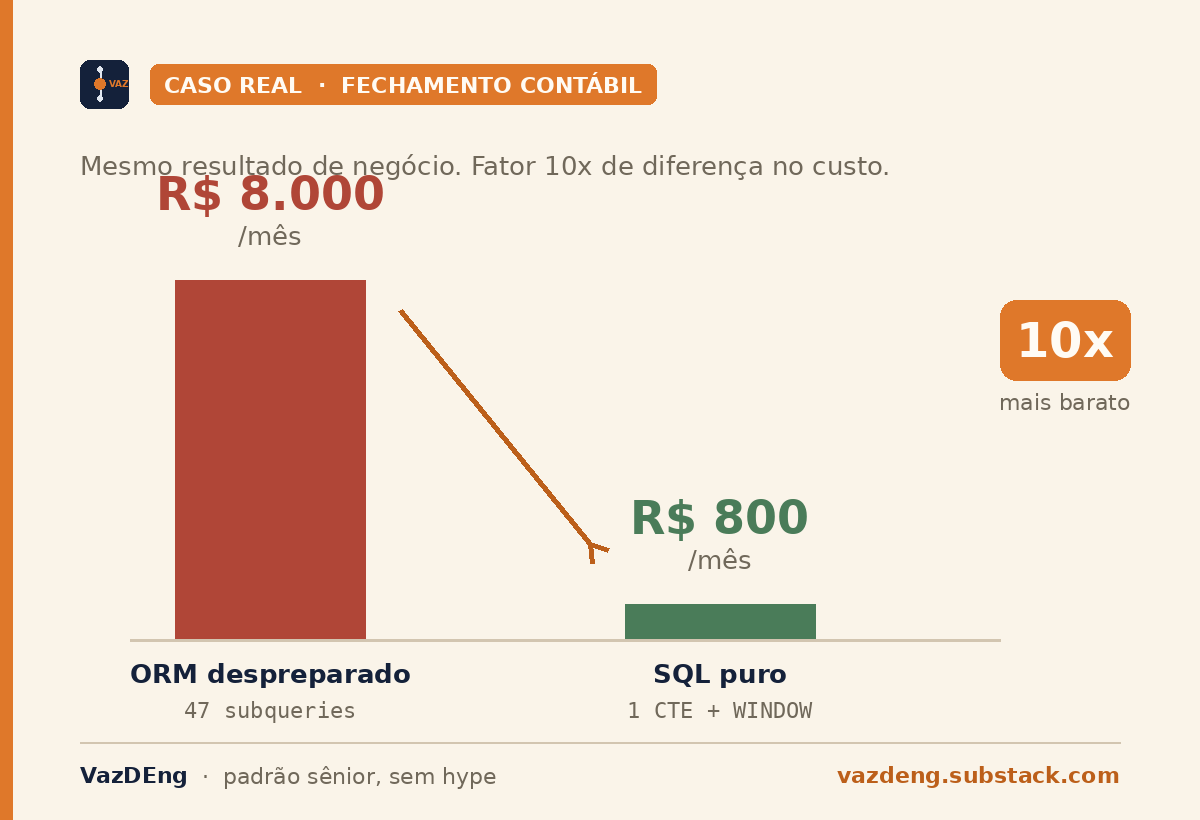
Não foi um caso isolado. É o padrão. Onde tem pipeline grande gerado por abstração, tem fator 10x de gordura esperando alguém ler o plan de execução.
A IA gera SQL ruim em escala
Toda IA generativa hoje gera SQL fluente. Compila, roda, retorna o número certo na primeira tentativa. O problema não é correção, é eficiência.
Padrões observados em SQL gerado por LLM sem revisão:
SELECT *em CTE empilhada, arrastando colunas que ninguém vai usar pelo pipeline inteiro.WHERE coluna IN (SELECT ... )em vez de JOIN, em casos onde o JOIN seria 100x mais rápido.WHERE UPPER(coluna) = 'X'em coluna indexada, derrubando o índice.- Sem hint de partition em Spark/Snowflake, lendo tabela inteira quando só precisa de 1 dia.
- Window function sem
PARTITION BYcorreto, computando coisa errada sem dar erro.

Desses cinco padrões, não tem um que eu não tenha visto em query gerada. Quem não lê plan de execução não vê. Vai pra produção, paga os juros no fim do mês. Dívida técnica com IA não é a mesma dívida de 5 anos atrás. Você contrai 10x mais rápido, achando que está levando vantagem.
O plan de execução é onde mora a diferença
EXPLAIN ANALYZE no Postgres. EXPLAIN COST no Snowflake. Plano físico no Spark UI. É a primeira coisa que eu olho antes de deixar query nova rodar em escala. Todos te dizem a mesma coisa: quantos rows o engine vai escanear, quais joins escolheu, onde tem shuffle, onde tem broadcast, onde tem fila de espera.
Codificador olha pro plan e não entende. Engenheiro lê e sabe se vale rodar em produção ou se precisa reescrever. Não é decoreba. É leitura de causa pra custo.
Quando você pede pra LLM gerar SQL, peça também o plan estimado, peça pra comparar com versão alternativa, peça pra discutir trade-off de partition vs broadcast. Se você não sabe avaliar a resposta, você não está fazendo engenharia ainda. Está terceirizando decisão.
A decisão é antes da próxima feature
SQL não morreu. Quem morreu foi quem fingiu que sabia.
A IA é darwinismo profissional. Quem aprende SQL de verdade fica 10x mais produtivo com ela, porque sabe avaliar o que ela gera. Quem terceiriza ORM mais IA acumula dívida que vai quebrar produção em 18 meses, e nesse dia não vai ter ninguém pra debugar porque ninguém mais lê plan de execução.
A escolha é antes da próxima feature. Vai aprender o que está rodando ou vai apostar que a IA cobre teu vão? A aposta é ruim.
Próximo post na quinta: prompt caching cortando 90% do custo de LLM em produção. Bench real, configuração em uma linha, onde brilha e onde não brilha.
Assina o VazDEng se ainda não assina. Engenharia de dados em português, padrão sênior, sem hype: vazdeng.substack.com.