
Vi a maioria dos times tratar LGPD como algo pra resolver “depois”.
Primeiro o pipeline é montado, os dados entram no lake, os dashboards começam a sair. Aí, um dia, chega uma requisição de titular pedindo exclusão de dados pessoais. E o time descobre que não sabe onde aquele CPF está, quantas cópias existem no Bronze, quantos modelos de ML já foram treinados com ele.
É tarde.
LGPD não é compliance no fim do pipeline. É uma restrição de design que começa no primeiro byte que você ingere. Existem quatro princípios que, se você incorporar logo na camada de ingestão, evitam praticamente todas as dores que vêm depois.
Princípio 1: minimize na fonte, não no destino
O Art. 6º, III da LGPD fala em necessidade: só trate dados adequados e limitados ao que é necessário para a finalidade.
A tradução prática que aprendi é simples. Não ingira o que você não vai usar.
Parece óbvio, mas não é. A maioria dos pipelines ingere tabelas inteiras (incluindo colunas de CPF, RG, telefone, endereço, e-mail) “porque está na fonte”. Aí o compliance chega, pede o mapeamento desses campos, e descobre que 80% deles nunca foram consumidos por ninguém.
O padrão correto é aplicar schema filtering antes da persistência. No pipeline de ingestão, você define explicitamente quais campos entram no lake. O que não entrar, não vira problema seu de retenção, de anonimização, de auditoria.
A pergunta que vale a pena fazer antes de cada campo é: qual caso de uso concreto precisa desse dado?. Se a resposta for “sei lá, pode ser útil”, é porque não precisa.
Princípio 2: pseudonimize desde o primeiro byte
Três termos que parecem iguais e não são.
Anonimização é o dado tornado irreversível. Não dá mais pra identificar ninguém. É o único estado que a LGPD trata como fora do escopo (Art. 12).
Pseudonimização é a identidade substituída por um código, mas com possibilidade de reverter via uma tabela separada. Continua sendo dado pessoal (Art. 13, §4º). Reduz risco, mas não remove a obrigação.
Tokenização é uma variante específica de pseudonimização com token determinístico, útil pra preservar joins sem expor o dado original.
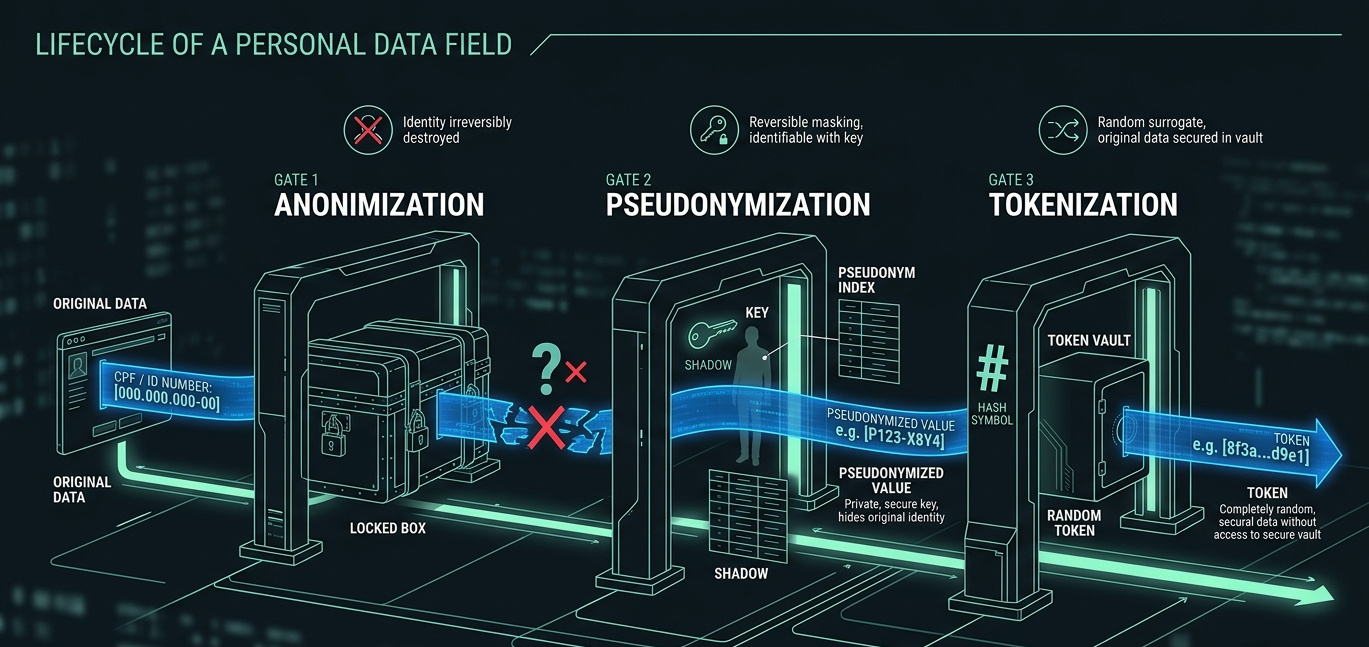
A prática que funciona é tokenizar na ingestão. O Bronze nunca vê o dado cru. Vê o token determinístico. O mapeamento token ↔ dado original vive numa tabela isolada, com criptografia em repouso, acesso auditado e política de retenção própria.
Isso resolve três problemas de uma vez. Você consegue fazer join entre tabelas no lake sem expor o dado original. Direito ao apagamento vira um DELETE no mapeamento, sem precisar mexer no Bronze. E analistas e modelos de ML trabalham com dados pseudonimizados por padrão, reduzindo a superfície de risco.
Princípio 3: lineage é requisito, não feature
Quando chega uma requisição de confirmação ou acesso (Art. 19 da LGPD), o controlador tem até 15 dias pra responder. Os direitos do titular (acesso, correção, exclusão) estão no Art. 18. Sem lineage completo, esse prazo vira pesadelo.
Lineage de verdade responde três perguntas pra qualquer dado pessoal. De onde veio? Sistema fonte, campo original, timestamp de ingestão. Que transformações sofreu? Passos do pipeline, regras aplicadas, derivações. Onde está agora? Tabelas, modelos treinados, dashboards que o consomem.
Ferramentas como OpenLineage, DataHub e o Unity Catalog do Databricks entregam isso, mas só se você instrumentar desde a ingestão. Colocar lineage depois que o pipeline já está rodando é dez vezes mais caro do que colocar antes.
O teste prático é direto: você consegue, em menos de uma hora, listar todas as tabelas e modelos que contêm o CPF 123.456.789-00? Se não consegue, seu lineage não está pronto pra LGPD.
Princípio 4: retenção por finalidade, não por tabela
O Art. 15 diz que o tratamento termina quando a finalidade for alcançada. O Art. 16 completa: depois disso, os dados devem ser eliminados.
Na prática da engenharia de dados, cada dado passa a ter um relógio próprio. Não dá pra criar uma política única de “retenção igual a 5 anos” pra todas as tabelas. Algumas finalidades exigem meses, outras anos, outras são indefinidas (por base legal diferente).
Padrões que funcionam: tabelas particionadas por data de tratamento, com VACUUM ou TRUNCATE PARTITION no fim do ciclo. Mapa de finalidades documentado em código, num YAML que define, por tabela e por campo, qual finalidade justifica, qual base legal e qual prazo. E jobs de expiração automáticos, sem confiar em processo manual: configura retention policies que rodam sozinhas.
Delta Lake, BigQuery e Snowflake têm mecanismos pra isso. O trabalho é traduzir finalidade jurídica em configuração técnica, e esse é o trabalho que ninguém quer fazer, mas que determina se você vai ou não bater de frente com a ANPD.
O que o time de dados precisa combinar com o jurídico
Três conversas que a engenharia não pode terceirizar.
A primeira é a base legal de cada dado. Consentimento? Legítimo interesse? Execução contratual? Cada base tem implicações técnicas diferentes. Direito de revogação, por exemplo, só existe em consentimento.
A segunda é a finalidade concreta de cada pipeline. “Analytics” não vale. Qual decisão de negócio esse dado suporta?
A terceira é o processo de resposta a requisições. Quem recebe? Qual o fluxo? Qual o SLA interno? Isso precisa estar documentado, testado e ter dono.
Se essas três conversas ainda não aconteceram, seu pipeline de dados pessoais está operando em dívida técnica de compliance.
O que fica
LGPD não é checklist no fim. É uma restrição de design que muda quatro coisas. O que você ingere (minimização). Como você ingere (pseudonimização). O que você rastreia (lineage). Por quanto tempo mantém (retenção por finalidade).
Times que tratam LGPD como “resolvemos depois” pagam o retrabalho inteiro na primeira requisição de titular que chega. Times que tratam como design constraint desde o primeiro byte nem percebem que ela está ali, porque é só como as coisas funcionam.
A diferença entre um e outro não é jurídica. É de engenharia.
Qual foi a requisição de titular mais cabulosa que você já viu chegar no seu time? Me responde no LinkedIn ou assina o Substack pra receber os próximos posts.