
No Slack do meu time aparece toda semana: “deve usar Delta Lake ou Parquet?”
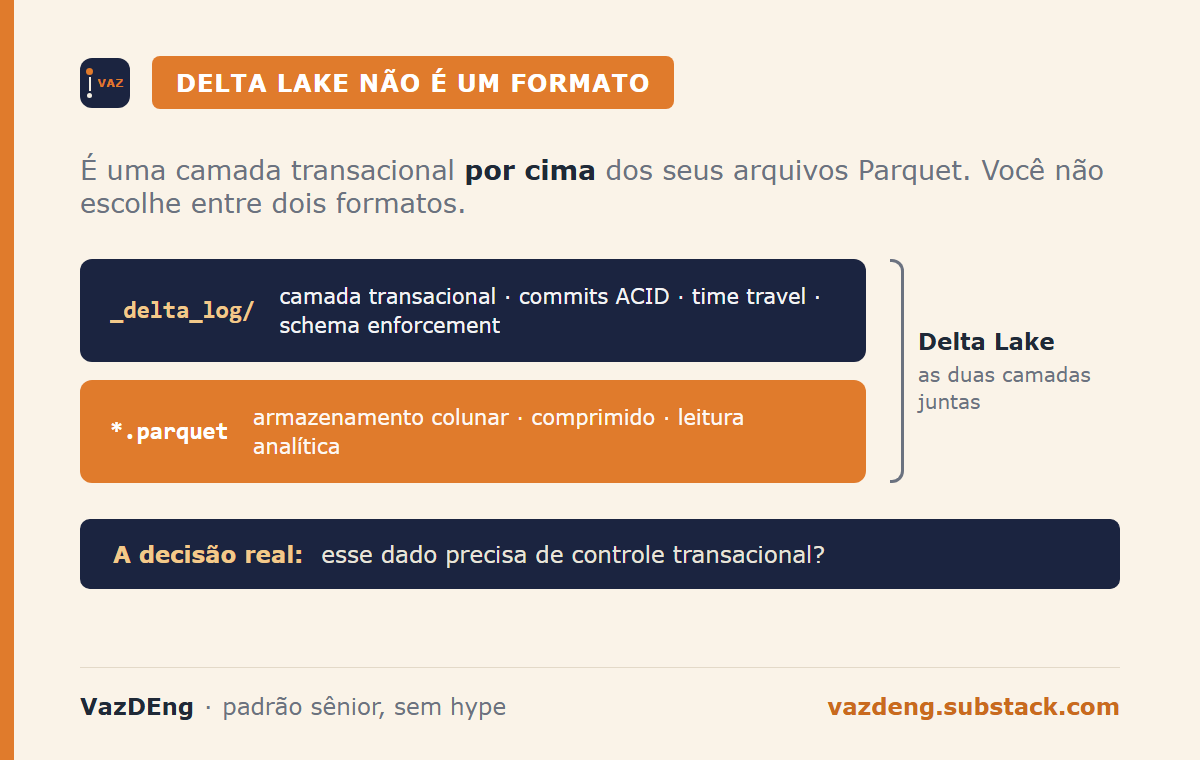
Delta Lake não é um formato de arquivo concorrente ao Parquet. É uma camada de gerenciamento transacional que armazena os dados em arquivos Parquet. Você não está escolhendo entre dois formatos. Está decidindo se precisa de uma camada transacional por cima dos seus arquivos.
Essa distinção muda o critério de decisão completamente. E confundir os dois em produção custa caro.
O que o Parquet não faz
Parquet resolve um problema específico muito bem: armazenar dados de forma colunar, comprimida, eficiente para leitura analítica. É o formato certo para isso.
O que Parquet não faz: controle de concorrência. Se dois jobs escrevem na mesma partição ao mesmo tempo, o resultado é não-determinístico. Sem transação, sem rollback, sem detecção de conflito. O arquivo que chegou por último vence. O outro desaparece.
Numa fintech onde trabalhei, com pipelines de ingestão distribuídos, isso não era teórico. Era o cenário padrão toda vez que um job de streaming e um job de backfill rodavam juntos na mesma tabela.
Em pipelines com job de streaming e backfill simultâneos esse cenário aparece sem aviso. O sintoma é sutil: contagem de linhas correta, valores que divergem do dia anterior sem nenhum erro no log. O último writer sobrescreveu o anterior. Silencioso e sem rollback.

O que o Delta Lake adiciona
Delta Lake resolve o problema de concorrência com o _delta_log: um diretório de commits JSON e checkpoints Parquet que registra cada transação. Todo writer registra o que adicionou, o que removeu e a versão resultante. Leitores veem estados consistentes, nunca parciais.
Isso habilita quatro capacidades que Parquet puro não tem:
Operações UPDATE, DELETE e MERGE sem reescrever a tabela inteira. O Delta marca os arquivos afetados como removidos e adiciona novos. O dado antigo fica acessível via time travel (SELECT * FROM tabela VERSION AS OF 10), mas não aparece nas consultas correntes.
Schema enforcement. Se um pipeline tenta escrever uma coluna com tipo incompatível, a escrita falha antes de contaminar a tabela. Com Parquet puro, você descobre o problema no consumidor, não na fonte.
Compactação controlada via OPTIMIZE. Ingestões de streaming geram dezenas de pequenos arquivos por hora. O Delta consolida esses fragmentos sem downtime, mantendo o log de transações intacto.
Data skipping usando estatísticas min/max por arquivo. Numa tabela de 2 TB com 10 mil arquivos Parquet, uma query filtrada por data precisa abrir potencialmente todos os arquivos para checar os metadados. O Delta mantém min/max de cada coluna no log e pula arquivos inteiros sem leitura.
Quando Delta Lake é excessivo
Delta Lake tem custo. O _delta_log adiciona overhead em escritas pequenas. O checkpoint é gerado a cada 10 commits por padrão. Para datasets imutáveis, o custo não tem contrapartida.
Três cenários onde Parquet é a escolha certa:
Datasets de referência que nunca mudam. Tabelas de código BACEN, tabelas de calendário, dados históricos selados após processamento. Nenhum escritor concorrente, nenhum update. Parquet direto, sem overhead de log.
Pipelines de exportação para sistemas externos. Você está gerando arquivos para enviar a um parceiro, um sistema legado, ou um bucket S3 consumido por ferramenta que não lê Delta. Parquet é o padrão de interoperabilidade.
Experimentos e dados efêmeros. Um notebook de análise que lê um arquivo CSV e salva o resultado. Não precisa de controle de versão nem de transação. O overhead do Delta não agrega nada aqui.
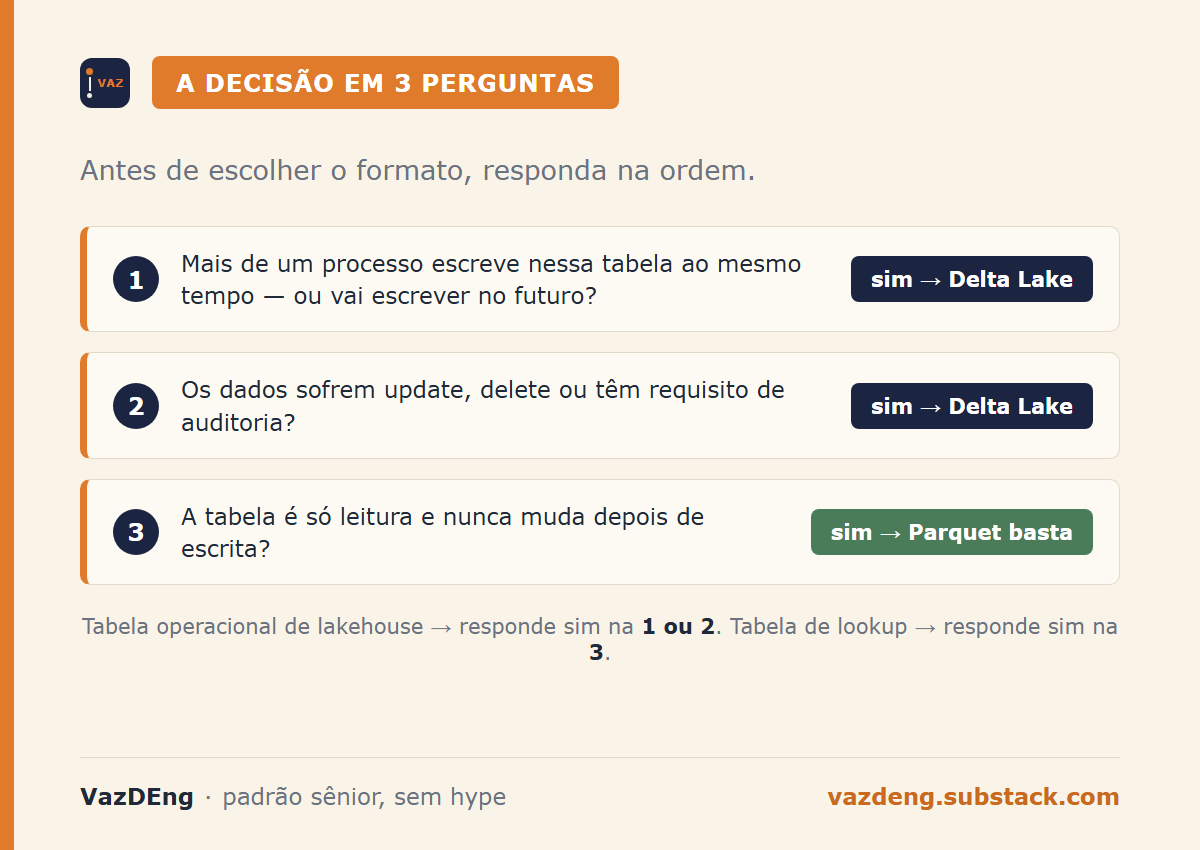
A decisão em três perguntas
Antes de escolher o formato, responda:
-
Mais de um processo escreve nessa tabela ao mesmo tempo, ou vai escrever no futuro? Se sim, Delta Lake.
-
Os dados são atualizados, deletados ou têm requisito de auditoria? Se sim, Delta Lake.
-
A tabela é consumida apenas por leitura e nunca muda depois de escrita? Parquet é suficiente.
A maioria das tabelas operacionais em um lakehouse produtivo responde “sim” para a primeira ou segunda pergunta. A maioria das tabelas de lookup responde “sim” para a terceira.
Em tabelas de auditoria de transações financeiras, onde você precisa reconstruir o estado em qualquer ponto do tempo e garantir consistência de schema, time travel e schema enforcement deixam de ser conveniência e viram requisito de engenharia. Parquet puro aqui não é só ineficiente, é frágil.
A decisão arquitetural real
Delta Lake não é uma versão melhorada do Parquet. É uma camada diferente que resolve um problema diferente.
O Parquet resolve: como armazenar dados de forma eficiente para leitura analítica.
O Delta Lake resolve: como garantir consistência quando múltiplos processos acessam o mesmo dado ao mesmo tempo.
A pergunta certa não é “qual formato usar”. É “esse dado precisa de controle transacional?” Se precisar, Delta Lake. Se não precisar, Parquet. Passei pelas duas direções em projetos diferentes. O errado custou caro nos dois lados.
Se você já encontrou corrupção silenciosa por concorrência em Parquet, ou se optou por Delta em algo que depois pareceu excessivo, conta nos comentários qual foi o contexto.