
The question comes up every week in my team’s Slack: “should we use Delta Lake or Parquet?”
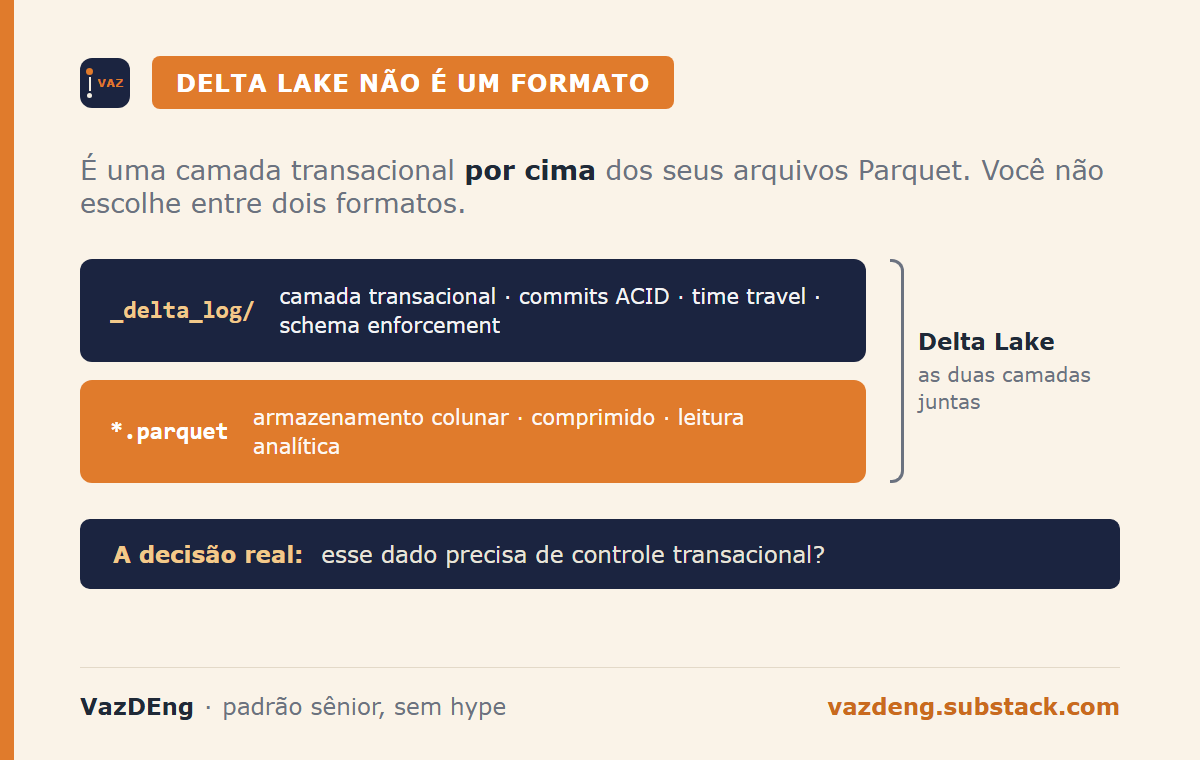
Delta Lake isn’t a competing file format to Parquet. It’s a transactional management layer that stores data in Parquet files. You aren’t choosing between two formats. You’re deciding whether you need a transactional layer on top of your files.
That distinction changes the decision criteria completely. And confusing the two in production costs real money.
What Parquet doesn’t do
Parquet solves one specific problem very well: storing data in a columnar, compressed format that’s efficient for analytical reads. It’s the right format for that.
What Parquet doesn’t do: concurrency control. If two jobs write to the same partition at the same time, the result is non-deterministic. No transactions, no rollback, no conflict detection. The last writer wins. The other one disappears.
At a fintech where I worked, with distributed ingestion pipelines, this wasn’t theoretical. It was the default scenario every time a streaming job and a backfill job ran together on the same table.
In pipelines with simultaneous streaming and backfill, the scenario shows up without warning. The symptom is subtle: row counts look right, but values diverge from the previous day with no error in the log. The last writer overwrote the previous one. Silent, no rollback.

What Delta Lake adds
Delta Lake solves the concurrency problem with _delta_log: a directory of JSON commits and Parquet checkpoints that records every transaction. Every writer registers what was added, what was removed, and the resulting version. Readers see consistent states, never partial ones.
That enables four capabilities pure Parquet can’t offer:
UPDATE, DELETE, and MERGE operations without rewriting the entire table. Delta marks affected files as removed and adds new ones. Old data remains accessible via time travel (SELECT * FROM table VERSION AS OF 10), but doesn’t appear in current queries.
Schema enforcement. If a pipeline tries to write a column with an incompatible type, the write fails before contaminating the table. With pure Parquet, you discover the problem at the consumer, not at the source.
Controlled compaction via OPTIMIZE. Streaming ingestion generates dozens of small files per hour. Delta consolidates these fragments without downtime, keeping the transaction log intact.
Data skipping using min/max statistics per file. In a 2 TB table with 10,000 Parquet files, a date-filtered query potentially has to open every file to check metadata. Delta keeps min/max per column in the log and skips whole files without reading them.
When Delta Lake is overkill
Delta Lake has a cost. The _delta_log adds overhead on small writes. Checkpoints are generated every 10 commits by default. For immutable datasets, that cost has no return.
Three scenarios where Parquet is the right choice:
Reference datasets that never change. BACEN code tables, calendar tables, historical data sealed after processing. No concurrent writers, no updates. Pure Parquet, no log overhead.
Export pipelines to external systems. You’re generating files to send to a partner, a legacy system, or an S3 bucket consumed by a tool that doesn’t read Delta. Parquet is the interoperability standard.
Experiments and ephemeral data. A notebook that reads a CSV and saves a result. No need for versioning or transactions. Delta’s overhead adds nothing here.
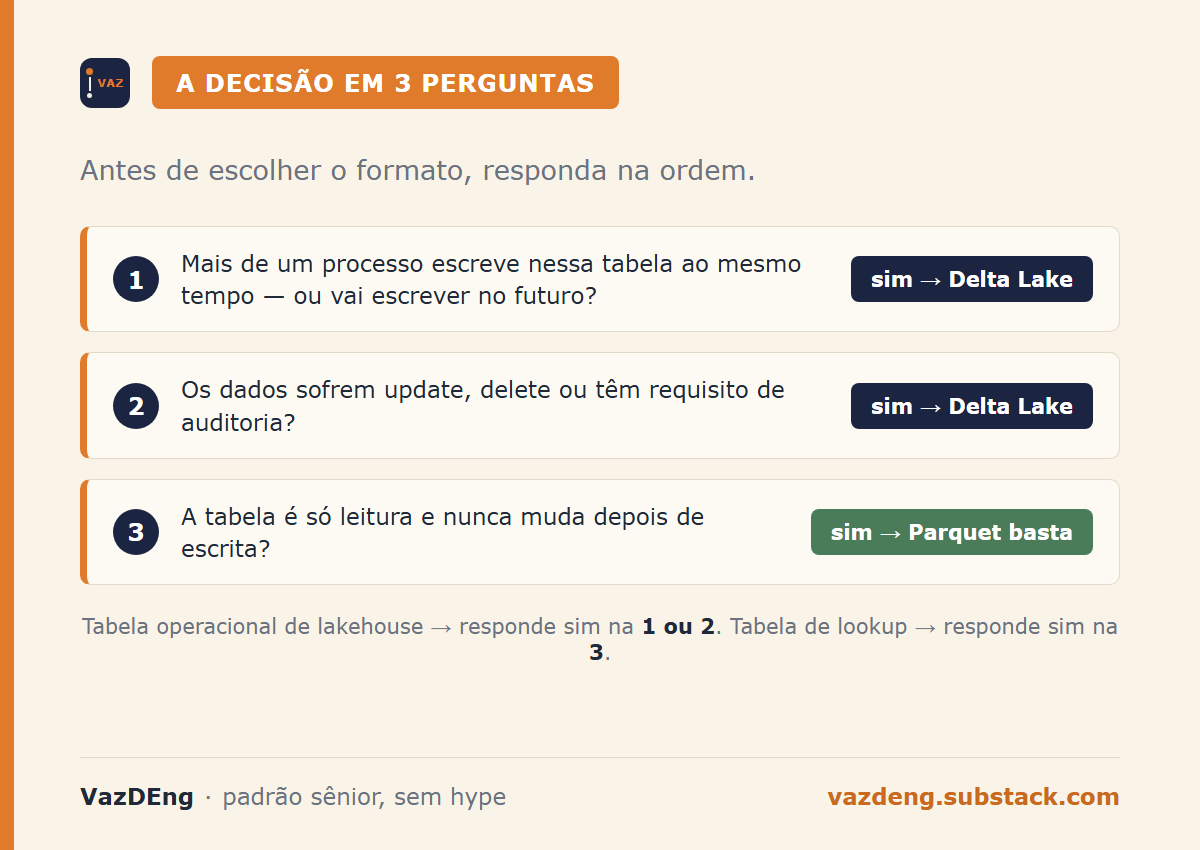
The decision in three questions
Before choosing the format, answer:
-
Does more than one process write to this table at the same time, or will it in the future? If yes, Delta Lake.
-
Is the data updated, deleted, or subject to audit requirements? If yes, Delta Lake.
-
Is the table read-only and never modified after writing? Parquet is enough.
Most operational tables in a productive lakehouse answer “yes” to question one or two. Most lookup tables answer “yes” to question three.
In audit tables for financial transactions, where you need to reconstruct the state at any point in time and guarantee schema consistency, time travel and schema enforcement stop being a convenience and become an engineering requirement. Using pure Parquet on those tables isn’t just inefficient. It’s fragile.
The real architectural decision
Delta Lake isn’t an improved version of Parquet. It’s a different layer that solves a different problem.
Parquet solves: how to store data efficiently for analytical reads.
Delta Lake solves: how to guarantee consistency when multiple processes access the same data at the same time.
The right question isn’t “which format should I use”. It’s “does this data need transactional control?” If it does, Delta Lake. If it doesn’t, Parquet. I’ve gone both ways across different projects. Picking the wrong one cost me on both sides.
If you’ve already hit silent corruption from concurrency in Parquet, or chose Delta on something that later felt excessive, share the context in the comments.