
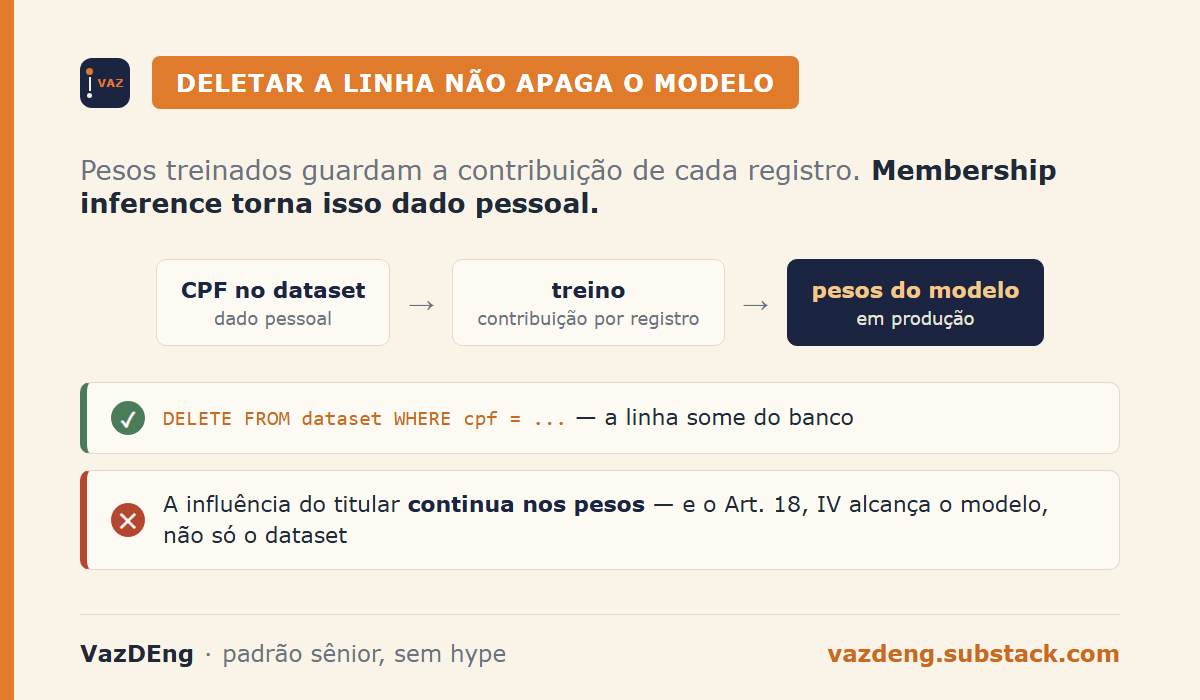
Um titular pediu exclusão dos dados. Você deletou a linha do banco. E o modelo?
Os pesos de um modelo de ML treinado com dados pessoais guardam, de forma não explícita, a contribuição de cada registro de treino. Deletar o dado original não apaga essa influência. Pesquisas de membership inference conseguem, com alguma probabilidade, determinar se um CPF específico fez parte do dataset de treino de um modelo. Isso é dado pessoal sob a LGPD.
Vi a maioria dos times sem processo para esse cenário. Não por falta de intenção: ninguém estabeleceu o fluxo antes de treinar o primeiro modelo.
O que o Art. 18 efetivamente exige
O Art. 18, IV da LGPD garante ao titular o direito de solicitar anonimização, bloqueio ou eliminação de dados “desnecessários, excessivos ou tratados em desconformidade”.
A interpretação que a ANPD vem sinalizando em suas consultas públicas sobre IA é que modelos de ML são processadores de dados pessoais quando os dados de treino eram pessoais no momento do tratamento. O modelo em produção herda essa classificação.
Se um titular pediu exclusão e você consegue demonstrar que os dados dele foram usados no treino, o direito ao apagamento se aplica ao modelo também. Não só ao dataset.
A lei não especifica como executar esse apagamento. Ela especifica o resultado esperado: o titular não deve mais ter influência sobre as decisões do modelo. Como você chega lá é problema técnico seu.
O problema técnico real
Três cenários que vi na prática, com dificuldades diferentes.
Dados genuinamente anonimizados antes do treino: se você aplicou anonimização real, não pseudonimização, antes de qualquer processamento de ML, está fora do escopo da LGPD para esse dado. O Art. 12 é claro: dado anonimizado não é dado pessoal. Mas anonimização precisa ser irreversível. K-anonymity com k=3 em transações financeiras não é anonimização real.
Dados pseudonimizados no treino: você substituiu o CPF por um token, mas manteve o mapeamento. O dado continua sendo pessoal. O modelo foi treinado com esse dado e agora está em produção. Um pedido de exclusão ativa o problema completo.
Dados brutos no treino, sem tratamento: o cenário mais comum em modelos mais antigos, treinados antes de qualquer preocupação regulatória. Também o mais difícil de resolver.
O que os times fazem na prática
Três abordagens que uso de referência, com trade-offs reais, nenhuma gratuita.
Retraining completo sem o dado: você remove o registro do dataset, retreina do zero ou a partir de um checkpoint anterior. É a abordagem mais limpa juridicamente, a mais defensável numa auditoria, e a mais cara computacionalmente. Para modelos que levam semanas para treinar, é impraticável como resposta rotineira.
Machine unlearning seletivo: técnicas que tentam remover a influência de registros específicos sem retreinamento completo. SISA training (Sharded, Isolated, Sliced, Aggregated) e gradient-based unlearning reduzem o custo. O problema: a maioria das implementações em produção ainda não tem certificação formal de que o apagamento foi efetivo. Numa disputa com a ANPD, “usamos machine unlearning” sem evidência mensurável não resolve.
Documentar a impraticabilidade e mitigar o risco: a LGPD permite, em alguns casos, a continuidade do tratamento quando o apagamento é impossível e existe base legal residual. Documentar que o modelo foi treinado com dados que à época tinham base legal, que o retraining é tecnicamente inviável, e que medidas de mitigação foram implementadas pode ser a resposta juridicamente defensável. Isso precisa de opinião jurídica, não só técnica.

Como arquitetar antes de treinar
O momento certo para resolver isso é antes do primeiro modelo ir para produção, não depois da primeira requisição de exclusão.
Versionamento de datasets por titulares: manter um índice de quais registros foram usados em qual versão de treino. Sem esse índice, você nem sabe quais modelos precisam de ação quando um titular pede exclusão.
Separação de dados de treino por consentimento: se parte do dataset veio de consentimento explícito e parte de legítimo interesse, trate como datasets separados desde o início. Quando o consentimento for revogado, você sabe exatamente qual subconjunto está comprometido.
Checkpoints rotulados por composição de dataset: se você usa treinamento modular, mantenha os checkpoints com metadados sobre quais shards foram usados. Isso reduz o custo de retraining seletivo de semanas para horas.

A decisão que todo time vai precisar tomar
O cenário vai aparecer: um titular envia uma requisição de exclusão, você deleta o dado, e alguém pergunta o que fazer com o modelo de score de crédito que usou esse CPF no treino.
A resposta honesta hoje é: depende de qual modelo, quando foi treinado, como o dataset foi gerenciado, e qual é a base legal original do tratamento.
O que não é mais aceitável é não ter a resposta. A ANPD está construindo sua posição sobre IA e LGPD. Os times que já documentaram suas decisões arquiteturais vão estar em posição muito melhor do que os que estão improvisando quando a orientação chegar.