
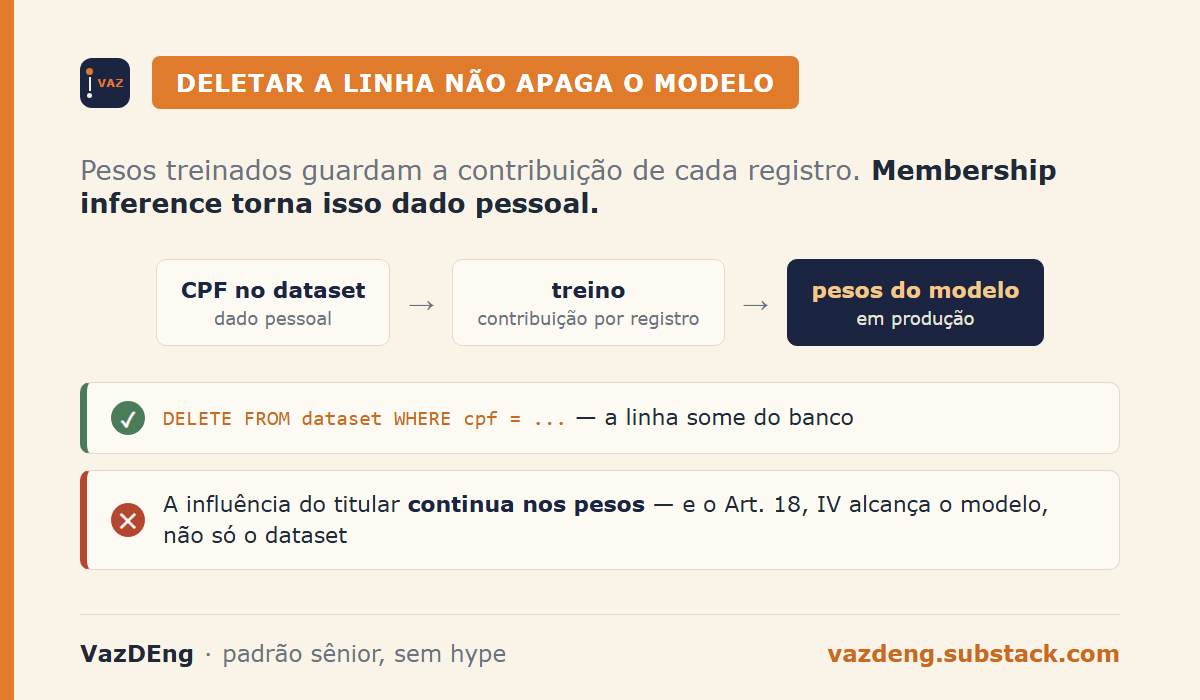
A data subject requested deletion. You deleted the row from the database. And the model?
The weights of an ML model trained on personal data hold, in a non-explicit form, the contribution of every training record. Deleting the original data doesn’t erase that influence. Membership inference research can determine, with some probability, whether a specific CPF was part of a model’s training set. That qualifies as personal data under LGPD.
I’ve seen most teams without a process for this scenario. Not for lack of intent: nobody set up the flow before training the first model.
What Article 18 actually requires
Article 18, IV of LGPD grants the data subject the right to request anonymization, blocking, or erasure of data that is “unnecessary, excessive, or processed outside compliance.”
The interpretation ANPD has been signaling in its public consultations on AI is that ML models are processors of personal data when the training data was personal at the time of processing. The production model inherits that classification.
If a data subject requested deletion and you can demonstrate that their data was used in training, the right to erasure applies to the model too. Not just to the dataset.
The law doesn’t specify how to execute that erasure. It specifies the expected result: the data subject should no longer have influence over the model’s decisions. How you get there is your technical problem.
The real technical problem
Three scenarios with different difficulty levels, that I’ve seen in practice.
Genuinely anonymized data before training: if you applied real anonymization, not pseudonymization, before any ML processing, you’re outside LGPD’s scope for that data. Article 12 is clear: anonymized data isn’t personal data. But anonymization needs to be irreversible. K-anonymity with k=3 on financial transactions isn’t real anonymization.
Pseudonymized data in training: you replaced the CPF with a token but kept the mapping. The data remains personal. The model was trained with that data and is now in production. A deletion request activates the full problem.
Raw data in training, no treatment: the most common scenario in older models, trained before any regulatory concern. Also the hardest to solve.
What teams do in practice
Three reference approaches I use, with real trade-offs, none free.
Full retraining without the data: you remove the record from the dataset, retrain from scratch or from an earlier checkpoint. It’s the cleanest legally, the most defensible in an audit, and the most expensive computationally. For models that take weeks to train, it’s impractical as a routine response.
Selective machine unlearning: techniques that try to remove the influence of specific records without full retraining. SISA training (Sharded, Isolated, Sliced, Aggregated) and gradient-based unlearning reduce cost. The problem: most production implementations still lack formal certification that the erasure was effective. In a dispute with ANPD, “we used machine unlearning” without measurable evidence doesn’t settle it.
Documenting impracticability and mitigating risk: LGPD allows, in some cases, continued processing when erasure is impossible and there’s a residual legal basis. Documenting that the model was trained with data that had a legal basis at the time, that retraining is technically unfeasible, and that mitigation measures were implemented can be the legally defensible answer. This needs legal opinion, not just technical analysis.

How to architect before training
The right moment to solve this is before the first model goes to production, not after the first deletion request.
Dataset versioning by data subject: maintain an index of which records were used in which training version. Without that index, you don’t even know which models need action when a data subject requests deletion.
Separation of training data by consent: if part of the dataset came from explicit consent and part from legitimate interest, treat them as separate datasets from the start. When consent is revoked, you know exactly which subset is affected.
Checkpoints labeled by dataset composition: if you use modular training, keep checkpoints with metadata on which shards were used. That reduces selective retraining cost from weeks to hours.

The decision every team will have to make
The scenario will show up: a data subject sends a deletion request, you delete the data, and someone asks what to do with the credit scoring model that used that CPF in training.
The honest answer today is: it depends on which model, when it was trained, how the dataset was managed, and what the original legal basis for processing was.
What’s no longer acceptable is not having the answer. ANPD is building its position on AI and LGPD. Teams that have already documented their architectural decisions will be in a far better position than those improvising when guidance arrives.