
On August 1st, 2012, Knight Capital lost $440 million in 45 minutes.
Not an algorithm bug. Not a market crash. One server out of eight received the new deploy, while another kept an old flag reactivated (Power Peg, 2003 code). The two ran in parallel. The result was a cascade of automated orders nobody could stop.
The SEC documented the case (Release No. 70694, October 2013, which counts over US$460 million in unwanted positions; the US$440 million is Knight’s own figure): the root cause was not a trading logic error. It was state inconsistency between servers that should have been in sync. In data engineering language, a broken data flow.
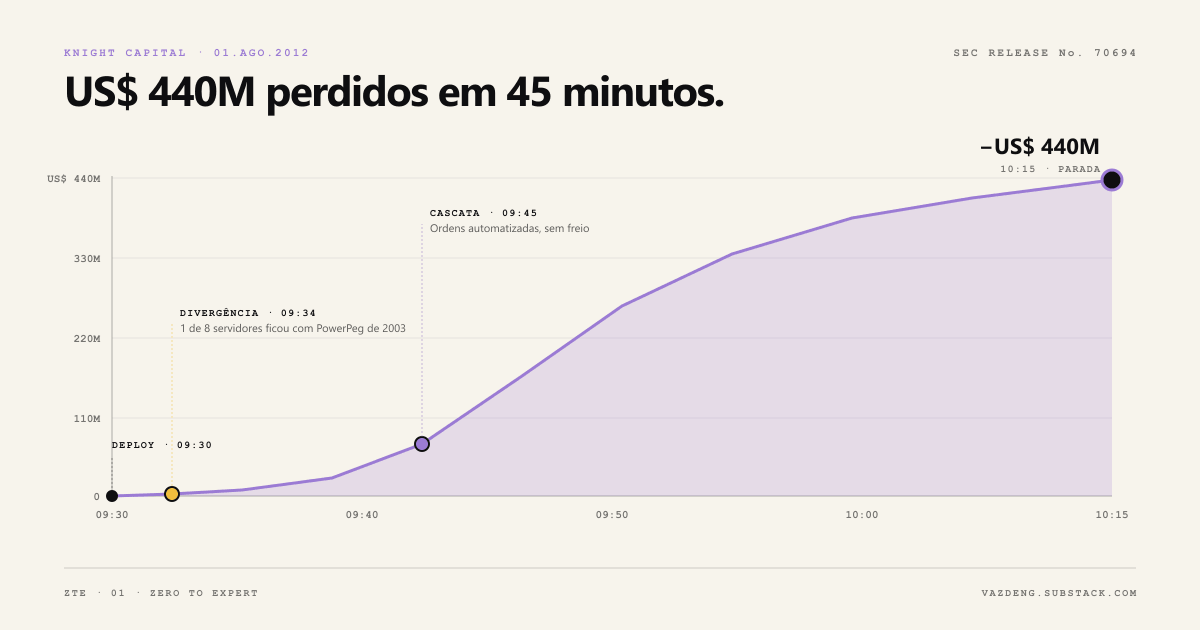
Knight Capital had sophisticated algorithms. Over a decade of operation. What it did not have was a clear mental model of where the data was born, where it traveled, and where it had to arrive consistently.
That mental model defines everything else. I have worked with data long enough to have seen, at smaller scales, variations of the same failure. Before Apache Spark, before dbt, before Snowflake, before any tool, there is a concept that separates a robust pipeline from a fragile one.
In one sentence
A data flow is the path data travels from source to destination, with every transformation in the middle. Getting that path right is an architectural decision. Getting it wrong is expensive.
Where this idea came from
It is not new. Bill Inmon published Building the Data Warehouse in 1992 defending top-down, normalized, enterprise-wide architecture. Ralph Kimball replied in 1996 with The Data Warehouse Toolkit: bottom-up, dimensional modeling, data marts composing the whole. The Inmon vs Kimball debate dominated the 90s and still shows up in any architecture review.
What changed between 1996 and 2026 was not the concept, it was the scale. In 2017, Martin Kleppmann published Designing Data-Intensive Applications and formalized in chapter 11 the distinction that organizes modern data engineering:
“A stream refers to data that is incrementally made available over time… in contrast to batch processing, where the input is a known, finite size.”
Bounded vs unbounded. A dataset with known size (batch) versus one that never ends (stream). Every data architecture decision starts here.
In 2021, the Lakehouse paper (Armbrust, Ghodsi, Xin, Zaharia, CIDR) proposed unifying warehouse and lake via a metadata layer (Delta, Iceberg, Hudi). In 2020, the dbt Labs team popularized ELT over ETL: transformation inside the warehouse, not before. Each wave changed the tooling, not the principle.
Bounded vs unbounded: the decision that defines everything
Every pipeline decision starts here. Practical summary in a table:
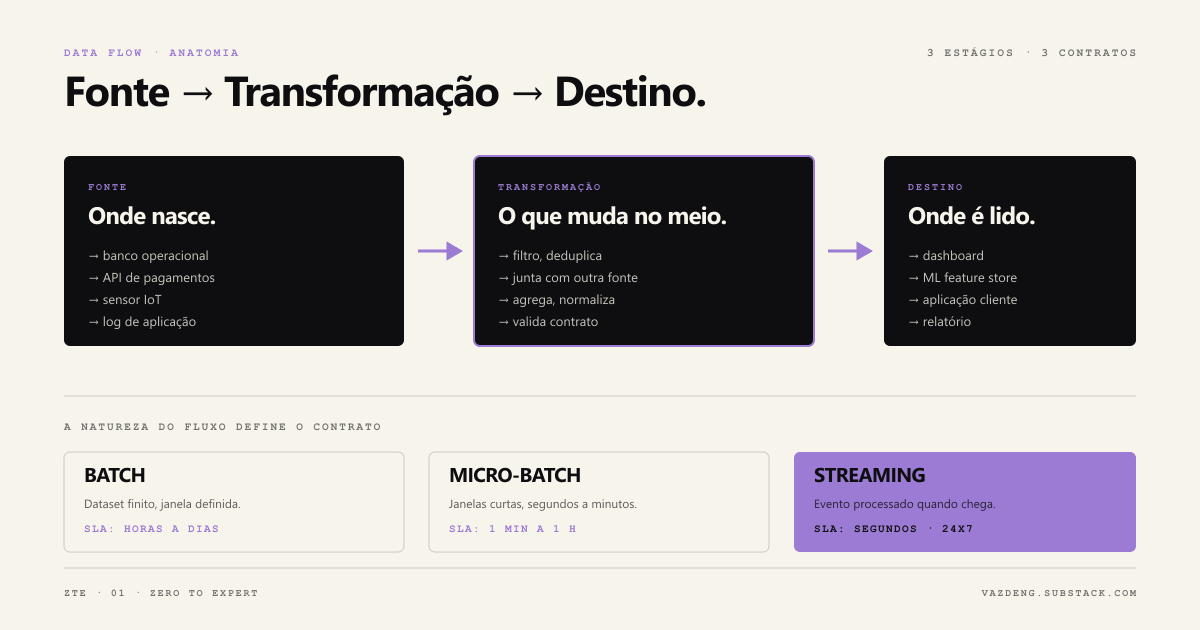
| Type | Trait | When to use | Cost |
|---|---|---|---|
| Batch | Finite dataset, processed in a defined window | SLA in hours, accounting reports, historical snapshots | Simple to build, debug, recover |
| Streaming | Infinite dataset, event processed on arrival | SLA from seconds to a few minutes, real-time fraud, ops dashboards | Complex, requires watermarks, exactly-once, heavy observability |
| Micro-batch | Streaming in short windows (seconds to minutes) | Middle ground: minute-level dashboards, ML feature stores near real-time | Spark Structured Streaming, Flink mini-batches |
Tyler Akidau and team (Google) published in VLDB 2015 The Dataflow Model paper that formalized the modern vocabulary: event time, processing time, watermarks, triggers, windowing. The central line:
“A practical approach to balancing the inherent tension between correctness, latency, and cost in massive-scale, unbounded, out-of-order data.”
Translation: streaming is right on three variables at the same time. You do not maximize the three, you pick two and pay for the third.
When batch, when streaming
The practical rule I use is simple: acceptable latency SLA defines the answer.
- SLA above 1h leans to batch. Simple reprocessing, direct debugging, cheap infrastructure.
- SLA below 1 minute demands streaming. Whoever tries to force batch in that scenario creates windows so short that it reinvents streaming with the worst of both worlds.
- SLA between 1 minute and 1h is micro-batch territory. Spark Structured Streaming or Flink mini-batches solve it.
Jay Kreps, Confluent founder, wrote in 2014 the essay Questioning the Lambda Architecture attacking the model proposed by Nathan Marz, which kept two parallel layers (batch + speed). The line that stuck:
“The problem with the Lambda Architecture is that maintaining code that needs to produce the same result in two complex distributed systems is exactly as painful as it seems.”
Kreps proposed Kappa: unified log (Kafka) as source of truth, reprocessing via replay. Kappa became standard among teams running serious streaming.
The most common mistake I see is forcing streaming because “it sounds modern”. Streaming is not a better version of batch. It is a different contract, different cost, different mental model. When the decision is taken by trend instead of by SLA, the team spends months building complexity the problem never asked for, and I have walked into that trap more than once.
What goes wrong when the flow is ignored
Knight Capital was not an isolated accident. The pattern repeats at other scales.
GitHub, October 2018: 24-hour outage. Root cause documented by Jason Warner (official post-mortem): 43 seconds of network partition between US East data centers caused divergence in MySQL Orchestrator failover, replication storm and cross-DC inconsistency. Pure data flow failure at the replication layer.
Airbnb, before Minerva: different teams calculated “active user” with divergent queries on the same Spark cluster. Metrics collided in executive meetings. The fix was not another dashboard. The solution was Minerva, a single metrics-definition layer (over 12,000 metrics and 4,000 dimensions) with explicit lineage from source to destination.
These cases fit named patterns in the literature. Worth knowing each:
- Pipeline jungle (Sculley et al, NeurIPS 2015, Hidden Technical Debt in Machine Learning Systems): “pipeline jungles often appear as data preparation evolves organically… testing such pipelines requires expensive end-to-end integration tests.” That is what happens when no one drew the flow at the start and it grew by accretion.
- Data swamp (Nick Heudecker, Gartner 2014): “lakes turn into swamps when there is no metadata, governance, or quality control.” Lake became a folder of files dumped anywhere.
- Schema drift: fields change without warning between runs, downstream contracts break silently.
- Lineage gaps: nobody knows where the dashboard number came from.
- Reverse-ETL chaos: data flows back from the warehouse to SaaS without governance, becomes a secret source of truth no one audits.
How the big ones document their own flow
Companies running real data in production publish the architecture. Worth reading.
| Company | Doc | Anchor |
|---|---|---|
| Netflix | Maestro: Netflix’s Workflow Orchestrator (TechBlog, Jul 2024) | Orchestrates hundreds of thousands of workflows per day, WAP (Write-Audit-Publish) pattern over Iceberg |
| Uber | Uber’s Big Data Platform (Eng Blog, Oct 2018) | Hudi cut ingestion latency from 24h to under 1h on 100+ PB |
| Airbnb | Democratizing Data at Airbnb (May 2017) | Dataportal indexes 200K+ data assets with explicit lineage |
| Stripe | Online migrations at scale (Eng Blog, Feb 2017) | Dual-write + backfill + reconciliation to migrate financial data without loss |
| Slack | How We Built Slack’s Data Warehouse (Sep 2023) | Presto+Hive to Trino+Iceberg migration, high volume of daily queries |
Common pattern: each one documented the flow before building the next tool. The tool was born from the diagram, not the other way around.
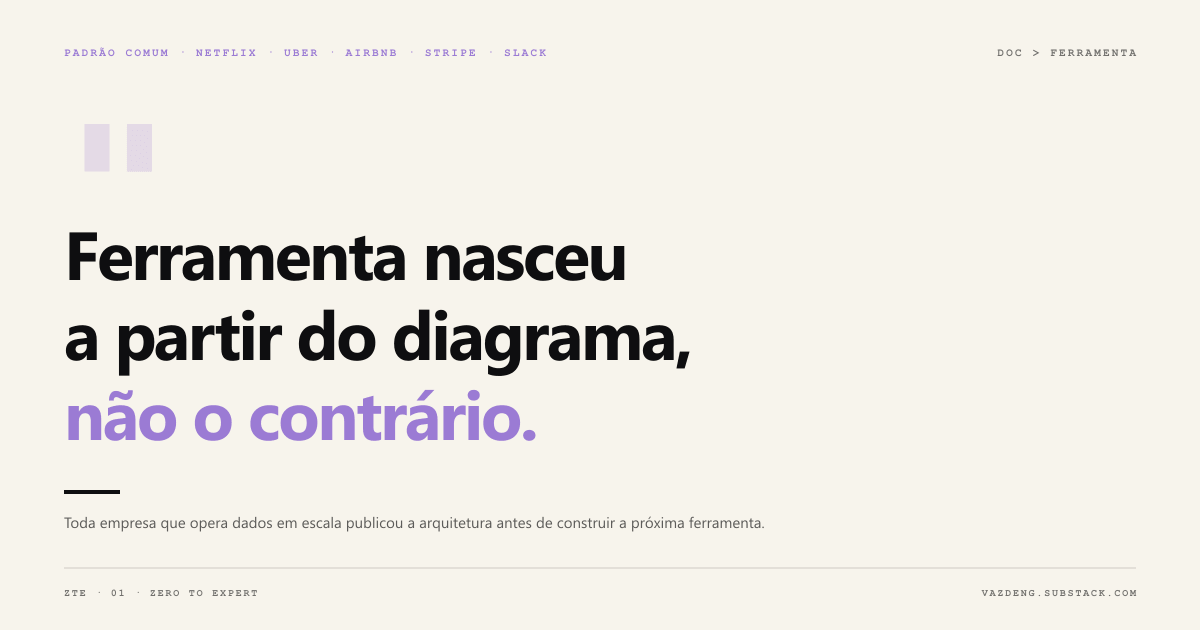
Anti-patterns to avoid
- Forcing streaming because it sounds modern. If the SLA is daily, batch solves it with 10% of the complexity.
- Building a pipeline without drawing the flow first. Pipeline jungle is literally this: growing without a map.
- Accepting the lake as “throw it all in, I will organize later”. Becomes a swamp in 6 months.
- Ignoring schema contracts. Schema drift breaks downstream silently. Use Schema Registry or versioned SQL contracts.
- Keeping two parallel implementations (Lambda). Maintenance cost doubles, behaviors diverge, no one trusts either.
- Skipping lineage. Lineage is not a luxury. It is the only way to answer “where did this number come from” without opening 12 jobs.
Where to start
Can you draw, on a napkin, the data flow of your most critical pipeline? Exact source, main transformations, destinations, SLA per stage.
If yes, you are ahead of most. If not, start there. Before Spark, before dbt, before any new tool.
The next episodes of the Zero to Expert series will go into each layer in depth: ingestion (formats, idempotency, CDC), transformation (SQL vs Python vs Spark), destination (warehouse vs lake vs lakehouse), orchestration. Each episode with a concrete case and a decision at the center, not theory.
If there is a specific concept you want covered, send it to me on LinkedIn or subscribe to the newsletter to get the next episodes.