
Hit HTTP 429 on 14 consecutive YouTube videos. I tried --sleep-subtitles 60, exponential backoff up to 45s, browser cookies, yt-dlp pre-release. Nothing helped. Every timedtext request came back 429.
Switched to the audio endpoint. Zero 429.
In one sentence: YouTube’s
timedtext(captions) andgooglevideo(audio/video) are different endpoints. Only the first is aggressively rate-limited in 2026. Downloading audio and transcribing locally is cheaper than insisting on captions.
The problem transcription pipelines ignore
The timedtext rate limit became common enough since 2025 that yt-dlp has 3 open issues (#7123, #13770, #13831) with no definitive fix. The official advice is caching and using the YouTube Data API with OAuth. Both work but shift the problem rather than solving it. Anyone who scheduled 50 URLs and saw half come back empty knows the symptom.
Why googlevideo doesn’t fall with it
The discovery that took me too long lives in the two distinct layers YouTube exposes. timedtext is an API layer: serves small XML/VTT under a global per-IP, per-day quota, with heavy caching and bot detection hardened in 2025. Every request counts. googlevideo is the CDN that serves audio and video via DASH segments from Google Global Cache edges, peering directly with your ISP. Its billing layer is aggregated bandwidth at the server serving your ISP, not per-request. The rate limit there only fires on clearly robotic patterns.
In practice I saw this: 60 requests in 5 minutes against timedtext results in guaranteed 429. The same 60 downloads on googlevideo with a natural interval go through with no warning. That detail isn’t documented in any obvious place. I figured it out when my cron broke and I opened Wireshark.

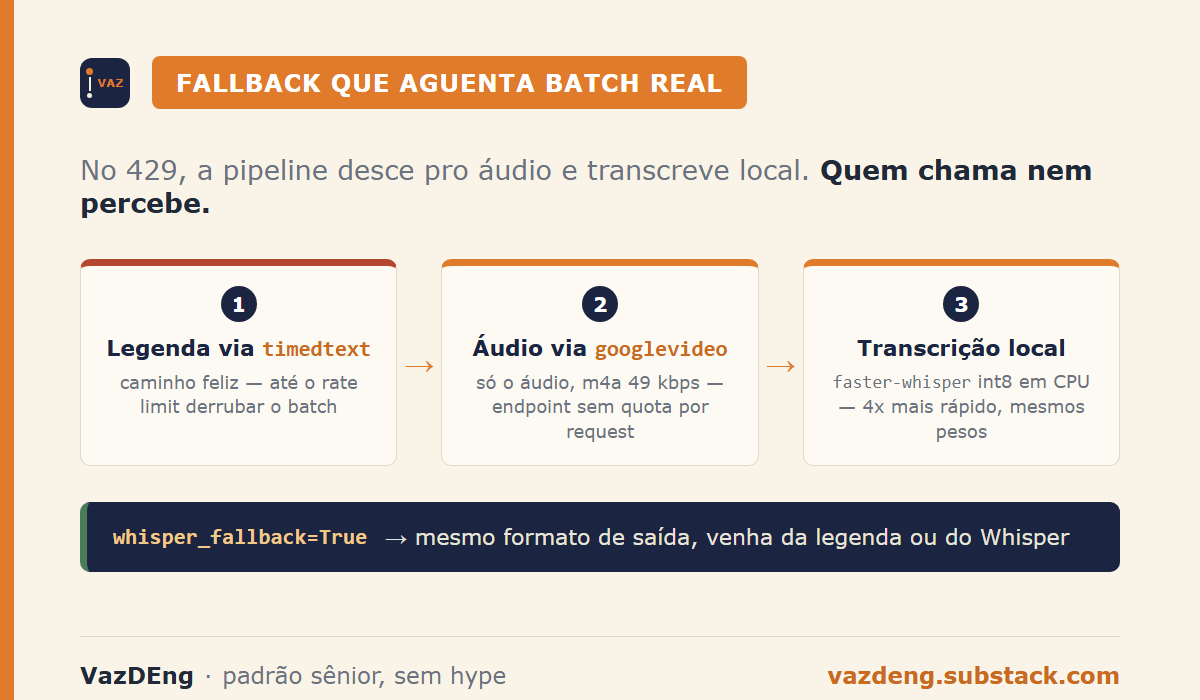
A pipeline that handles real batch loads
I packaged the logic in an open source Python CLI called yt-nota. Combines 3 tools.
| Step | Tool | Cost | Where it fails |
|---|---|---|---|
| Metadata + caption URL | yt-dlp (Python API) |
$0 | Private video, region lock |
| Audio fallback | yt-dlp format 139 (m4a 49kbps) |
$0 | Members-only without cookie |
| Local transcription | faster-whisper int8 CPU |
$0 | Video > 1h on weak hardware |
faster-whisper is 4x faster than openai-whisper on the same model, with the same accuracy (same weights). My CLI’s API looks like this:
result = extract_transcript(
url,
whisper_fallback=True, # default on
whisper_model="small", # or tiny/base/medium
)On 429, it drops to googlevideo, downloads only the audio, transcribes, and returns the same format. The caller doesn’t know if the transcript came from timedtext or Whisper.
CPU benchmark (Intel i7 12th gen, 16 GB, int8)
I ran the pipeline on real videos of varying length to measure wall-clock time. No GPU.
| Video duration | base (74 MB) |
small (244 MB) |
medium (769 MB) |
|---|---|---|---|
| 5 min | 35 s | 1 min 30 s | 5 min |
| 13 min | 1 min 50 s | 4 min | 13 min |
| 45 min | 6 min | 14 min | 45 min |
On accuracy for technical Portuguese, I did comparative reading over ~14 hours of lecture audio. The base model confuses 1 in every 6 technical terms (95% readable but needs human review). The small confuses 1 in every 20 (default for a reason: the downstream LLM corrects rare errors from context). The medium gets close to zero errors but doubles the time. For my flow (transcript → synthesis via Claude Code), small is the sweet spot.

What about SaaS with Whisper fallback?
They exist. Two main ones in 2026.
| Solution | Price | When it makes sense |
|---|---|---|
| Supadata | plans from $17/month (3,000 credits), free tier 100 credits/month | Company with SLA, doesn’t want to maintain infra |
| Apify YouTube Transcript Scraper | from ~$0.50 per 1,000 runs (varies by actor) + compute | Pipeline already on Apify |
| yt-nota self-host | 250 MB deps + 244 MB model | Privacy, academic batch, full control |
The call is trivial for me: learning notes and Obsidian vault don’t go through third-party APIs. If it were a corporate pipeline with SLA and audit, Supadata wins on operational simplicity. Self-host only makes sense when you are the customer of the data.
Honest verdict
What works: batch of 50+ videos without crashing midway, zero recurring cost after the initial 500 MB, quality on technical Portuguese good enough for an LLM to digest downstream.
What it costs: first install is heavy (pip install yt-nota[whisper]), small model can confuse exotic terminology (for critical audio, bump to medium), and CPU becomes a bottleneck on videos longer than 1h.
When NOT to use it: volume of 10,000 hours per month with tight SLA (OpenAI’s Whisper API at $0.006/min ends up cheaper per engineer-hour than running local infra), or audio with music and multiple simultaneous voices (faster-whisper doesn’t do diarization, pyannote does).
Anti-patterns I saw along the way
Trusting --sleep-subtitles 60 as a silver bullet. I tested it: it doesn’t trigger before the request, it triggers after the first 429. Game over. Reaching for a paid API before trying the local pipeline is also a trap. $36k/year on transcription (my estimate) is money that should buy you a mid-range GPU. And deleting the raw audio after transcribing is the mistake of someone who never wanted to re-run with a better model 6 months later. I keep mine.
What this changes for you
If you use YouTube as a learning source, RAG input, or note-taking pipeline:
- Does your current pipeline handle 50 URLs in a row without crashing?
- Can you tell a 429 from
timedtextapart from a 429 fromgooglevideo? - Do you have automatic fallback or do you handle each failure manually?
- Does your monthly transcription bill still fit, or has it passed the cost of an amortized GPU?
If you said “no” to more than one, it’s worth an afternoon of refactoring.