
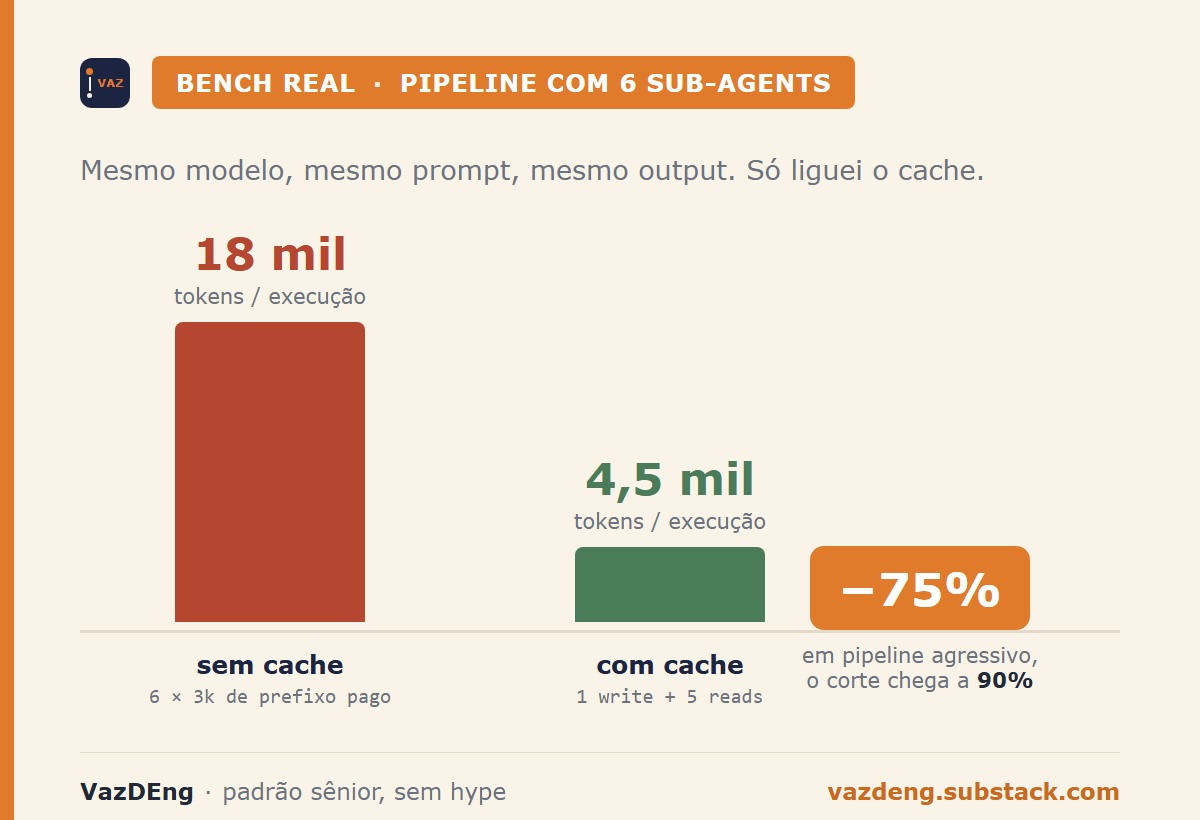
18 thousand tokens. That was the cost of every run of my news pipeline with 6 parallel sub-agents. After one line of code, it became 4,500. Same model. Same prompt. Same output. I just turned on the cache.
The feature has been in the Anthropic API for over a year. Most teams running LLMs in production still haven’t turned it on. I myself ran for months paying full price before actually reading my invoice. It’s the highest return per minute of work I know of today.
Why LLM cost in production is prefix
Every API call sends 4 things: system prompt, few-shots, context, and the question. In a real pipeline, the first 3 add up to 80 to 95 percent of the tokens, and they repeat on every call. The question changes. The rest is prefix.
Without cache, you pay for the entire prefix every time. In a pipeline running dozens or hundreds of times an hour, that becomes the bill. In a pipeline with parallel fan-out (several sub-agents sharing the same system prompt), it becomes the bill times the number of sub-agents.
With cache, you pay for the prefix once (cache write), then only the delta of each new call (cache read). A cache read costs about 10% of the normal input price.

How Anthropic’s cache works
You mark a block of the prompt with cache_control: ephemeral. Simplified example:
"system": [
{
"type": "text",
"text": "<long, stable system prompt here>",
"cache_control": {"type": "ephemeral"}
}
]Default TTL is 5 minutes. Next call inside that window: the cached prefix is read at 10% of the normal price. Anthropic also offers a 1-hour TTL as a paid option, useful for more spaced-out workflows.
The API returns 2 metrics you need to monitor:
cache_creation_input_tokens: you paid the write.cache_read_input_tokens: you paid only the read (90% discount).
No model change, no prompt rewrite. Just flag what’s cacheable.
A real benchmark from my daily news pipeline
The number in the opening comes from a pipeline I built and maintain: my daily news skill, running every day at 8am. It fires 6 parallel sub-agents: data engineering, AI, investing, crypto, local politics, international politics. Each one carries a fixed system prompt of roughly 3 thousand tokens with tone rules, output format, prioritized sources, and synthesis style.
Without cache, the bill I was paying is direct math:
- 6 sub-agents × 3 thousand prefix tokens = 18 thousand tokens paid per run.
- Times 1 run per day = 540 thousand tokens a month on prefix alone.
With cache:
- 1 initial cache write (3 thousand tokens) + 5 cache reads (with a delta of ~300 tokens each) = ~4,500 effective tokens.
- Roughly a 75% cut in prefix cost, with zero quality loss and not a comma changed in the output.
In a more aggressive production pipeline (running dozens of times an hour with larger prefixes), the cut reaches 90%.
Where it shines, where it doesn’t
Shines:
- Large, fixed system prompt (rules, format spec, examples).
- Fan-out: several sub-agents with the same prefix in the same session.
- Agents looping over the same context.
- Chat with a large attached document and several consecutive questions.
Doesn’t shine:
- One-shot calls with no repeated pattern.
- Prompts that change significantly on every call.
- Workflows with more than 5 minutes between calls (the cache expired).

Caveats that kill the gain if you don’t know them:
- A cache write is slower than a normal call. You pay once in latency, you win on every call after. In a nightly pipeline that’s irrelevant. In an interactive chat, it matters.
- Don’t cache PII or sensitive data without auditing first. Anthropic’s cache is per-account, but the principle stands.
- The 5-minute TTL is a short window. If your job re-runs the pipeline every 10 minutes, the cache never hits. For those cases, use the 1-hour TTL.
- You only see the gain if you monitor the 2 metrics. A timestamp at the top of the system prompt is enough for the prefix to never cache, and without watching
cache_readyou think you turned it on and you didn’t.
It’s not micro-optimization. It’s architecture.
Whoever is paying 100% of the price of every call because “there was no time to configure it” is accumulating debt with Anthropic every month. In a production pipeline with serious volume, that becomes thousands of dollars a year. For one line of code.
The rule I now follow in everything I build: structure the prompt in layers. Stable first (cacheable), volatile last. Mark the stable part with cache_control: ephemeral. Monitor cache_creation and cache_read. Pay once, read many.
It’s the ABC. And there are still teams calling this “advanced optimization”.