
For 6 months, I built a quant agent for BTC/USDT trading.
Goal: maximize returns.
Result: Sharpe ratio of -1.14. Not good.
The system didn’t fail. It failed at one objective (alpha) and excelled at another (capital preservation).
Architecture by layers
Quant trading is complex. It’s not “buy here, sell there.” It’s this:
L1: Ingestion (real data)
L2: Processing (signals)
L3: Intelligence (predictions)
L4: Decision (sizing)
L5: Execution (minimize impact)
L6: Evaluation (backtests)
L7: Compliance (audit)Each layer is independent. Each has fallbacks.

L1: Ingestion
- BinanceFetcher: OHLCV, funding rates, open interest, order book
- MacroFetcher: DXY, S&P 500 via yfinance
- GlassnodeFetcher: on-chain metricsWhy 3 sources? Triangulation. If Binance goes down, you still have macro + on-chain.
L2: Processing
32+ technical indicators:
- RSI, MACD, Bollinger Bands (classics)
- ATR, Stochastic, Williams %R (volatility)
- Volume profile, Time-weighted moving average
- On-chain: MVRV, SOPR, Cumulative delta
- Macro: VIX-like crypto index
Everything normalized (z-score, min-max).
Everything temporally aligned (no forward-looking bias).L3: Intelligence
Gaussian HMM (Hidden Markov Model) with 3 states:
BULL (uptrend) → RSI > 60 + momentum + macro positive
SIDEWAYS (range) → RSI 40-60 + low volatility
BEAR (downtrend) → RSI < 40 + momentum negativeLightGBM regressor predicts returns on the next 4 candles (walk-forward).
You don’t need 60% accuracy to have alpha. You need consistency. A model that’s right 45% of the time but with low drawdown beats one that’s 70% accurate with 30% max DD.
L4: Decision
Quarter Kelly sizing. Not full Kelly (too aggressive).
Position size = (edge * odds) / odds_ratio
Capped at 2% of portfolio (max risk per trade)
Guardrails (non-negotiable):
- Max drawdown: 15%
- Circuit breaker: 3 consecutive losses = pause
- Kill switch: manual override always availableL5: Execution
Almgren-Chriss (minimize market impact):
Don't execute 100% in 1 candle.
Break it into 5-10 small orders.
Use TWAP/VWAP for better timing.
Check liquidity before each order.L6: Evaluation
Walk-forward backtesting (no data leakage):
Train window: 60 days
Test window: 5 days
Roll forward: shift 5 days, repeat
Metrics:
- Sharpe, Sortino, Calmar ratios
- Max drawdown
- Win rate
- Recovery factorL7: Compliance
- KillSwitch thread-safe (emergency)
- Auditor append-only in JSONL (immutable)
- Telegram notifications (real-time alerts)
- 202 tests (Python, pytest)
- CI/CD (GitHub Actions)The insight: Quant engineering isn’t about “predicting prices.” It’s about building a system that’s tested, auditable, and fails gracefully (minimal drawdown).
The Bug That Revealed Everything
Initially, Sharpe was +0.66. Looked good.
Then I found data leakage in the HMM: the model was seeing the future during training.
A simple oversight:
# WRONG: trains with all data (future data leaks)
hmm.fit(all_indicators)
# RIGHT: trains only with past up to time T
hmm.fit(indicators_until_date_T)After fixing: Sharpe dropped to -1.14.
That moment was crucial: real » spurious.

I could have:
- Ignored the bug and shipped (risk: fraud)
- Abandoned the project (risk: missed learning)
Instead, I documented the fix, rewrote the tests, and asked the right question: “What does this system actually solve?”
The Tradeoff: Alpha vs Capital Preservation
Let’s look at the numbers (out-of-sample, walk-forward):
| Metric | Quant Agent | Buy & Hold |
|---|---|---|
| Sharpe ratio | -1.14 | -0.04 |
| Max drawdown | 0.29% | 26.24% |
| Win rate | 1/7 windows | 4/7 windows |
Read that again.
The agent has no alpha. But it reduces drawdown by ~90x.
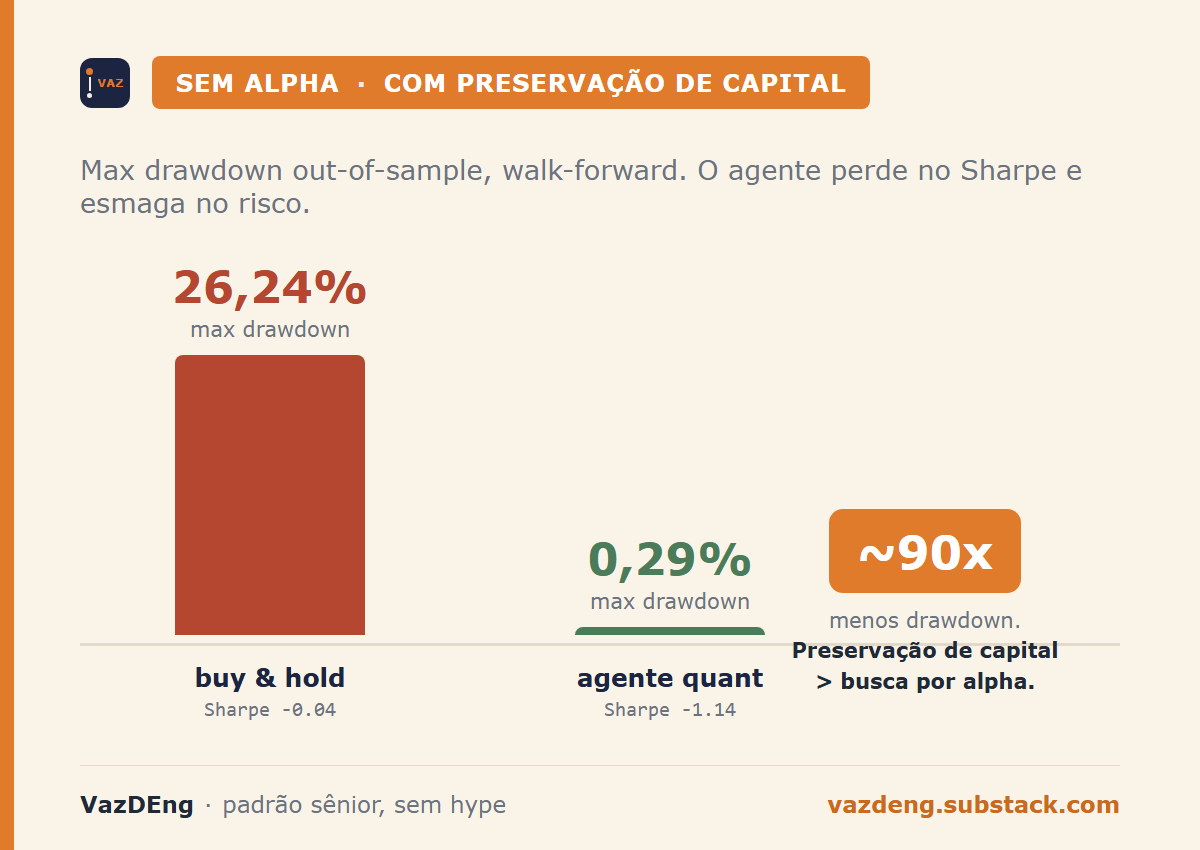
Ask yourself: which scenario would you prefer?
Scenario 1: You buy and hold. In one year, there’s one day where you lose 26% of everything. The next day, you recover 15%. Do you sleep?
Scenario 2: You’re running the agent. Max loss is 0.29% on any given day. You sleep better.
Capital preservation > chasing alpha.
Framework vs Outcome
The code didn’t “fail.” It solved a different problem than planned.
Systems thinking:
- Original goal: Generate positive returns (alpha)
- Problem discovered: Alpha is rare (even for professionals)
- Emergent solution: Risk management is consistent
- Actual result: A capital preservation system
Sometimes, failing at your original goal is the universe’s way of showing you the real one.
The Technical Stack
For devs, here’s what worked:
What worked:
- Python + SQLAlchemy (robust ORM)
- asyncio (true concurrency, non-blocking I/O)
- pytest (202 tests passing)
- Postgres (append-only auditing, compliance)
- Windows Task Scheduler (low-cost orchestration)
What was challenging:
- HMM on non-stationary data (quant is hard)
- Market microstructure (Almgren-Chriss is complex)
- Real-time data latency (lag = real slippage)
Final stack:
Data ingestion: Binance API + Glassnode + yfinance
ML stack: scikit-learn (HMM), LightGBM (regression)
Backend: FastAPI (optional, current: local scheduler)
Database: Postgres 16 + JSONL audit trail
Notifications: Telegram bot + Discord webhook
Infrastructure: Cheap VPS (1 vCPU, 4GB RAM, 50GB NVMe)Runs on a cheap machine. No Kubernetes, no scary AWS bills.
Lasting lessons
1. Test First (TDD)
202 tests = confidence. You refactor without fear.
No tests? Silent failures. You discover them in production.
Each feature has an associated test:
- test_hmmpredict.py (model validation)
- test_kelly_sizing.py (risk management)
- test_market_impact.py (execution)
- test_audit_trail.py (compliance)2. Auditing is Design
JSONL append-only logs saved me when I questioned results.
{"timestamp": "2026-04-22T10:30:00", "action": "BUY", "size": 0.05, "price": 65000, "reason": "BULL_regime_high_momentum"}
{"timestamp": "2026-04-22T11:45:00", "action": "CLOSE", "pnl": 50, "drawdown": 0.0015}You can trace why each decision was made.
3. Constraints Generate Innovation
Quarter Kelly sizing is more conservative than full Kelly. But it was more effective.
Constraints (2% max risk, 15% max DD) forced creativity in decision-making.
Too much freedom = overfitting.
4. Real-Time is Different from Backtesting
Walk-forward validation prevents surprises.
Your model might be 70% accurate in backtest, but in production? 45%. Why?
- Slippage (you don’t get the exact price)
- Latency (0.5s delay = different price)
- Spread (bid/ask widens in volatility)
Real-time doesn’t forgive.
5. Failure is Learning
Data leakage (-1.14 vs +0.66) was the most valuable discovery.
Fixing that bug = I learned more than from 10 books on quant.
Don’t fear “failures” that teach.
6. Simplicity > Complexity
3 states in the HMM worked better than 10+ features.
6 months building. Result: simple.
Time inversion: 95% building, 5% simplifying. But that 5% = the code that actually runs in production.
7. Capital Preservation > Chasing Alpha
Your goal should be: “Don’t lose money.”
Alpha (extra returns) is a bonus.
Most quants invert it: “I’ll chase alpha, tolerate losses.”
Wrong.
What Comes Next
This agent won’t generate overnight wealth.
(If anyone promises that, run.)
But it solves a real problem:
“How do I build a robust decision system in Python?”
Next steps for you:
- The code: project closed for now. The architecture described above (HMM + LightGBM + Kelly + HRP, train/production separation, event-based vs polling) is what matters to replicate the approach.
- Adapt it: For stocks, commodities, crypto (framework is agnostic)
- Realize: How hard quant is. Respect those who do it well.
What’s Your Metric?
Sharpe is useful. But maybe you optimize for something else:
- Maximum wealth in minimum time? (time allocated)
- Minimum drawdown? (peace of mind)
- Minimum capital needed? (accessibility)
Pick your metric. Build for it. Validate with real data.
Not his choice. Not the trend. Yours.
Sharpe -1.14 is a marketing failure. But it’s an engineering win.
If the goal was to learn how to build a robust, tested, auditable, scalable system, mission accomplished.
Your next objective is yours.
Reply on LinkedIn or subscribe to the Substack newsletter to get the next posts.